Ở bài viết trước, tôi đã đề cập đến việc custom 1 UITableViewCell. Tuy nhiên, việc sử dụng UITableView cũng còn khá nhiều điều cần phải quan tâm khác. Trong bài viết này, tôi sẽ đề cập đến những vấn đề ấy:
Lưu ý khi dùng định danh cho UITableViewCell
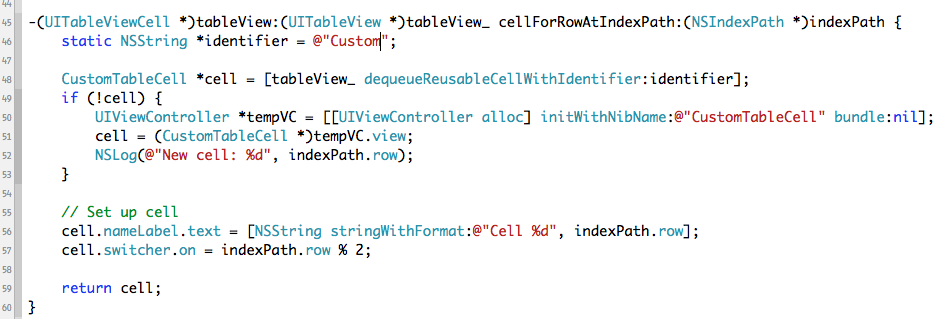
Trong quá trình tạo hiển thị, UITableView sẽ lưu lại các cell bị che khỏi màn hình hiển thị (ko phải render) trong 1 stack. Các Cell này sẽ được sử dụng lại khi mà 1 cell mới xuất hiện trên màn hình. Điều này giúp cải thiện tốc độ load table cell và ko làm tăng thêm bộ nhớ cho chương trình. Khi lấy cell trong stack ra, UITableView sẽ sử dụng định danh đã nói ở trên để lấy được các cell cùng kiểu. Chính vì thế định danh này phải được đặt giống với trường identifier trong file xib. Nếu không, các cell của table sẽ không bao giờ được sử dụng lại. Có thế test điều này trong ví dụ: trường identifier trong file CustomTableCell.xib đặt là “CustomTableCell” và định danh trong code đặt là “Custom”, khi chạy chương trình, điều kiện if (!cell) sẽ luôn luôn xảy ra => tức là table view sẽ luôn tạo ra cell mới chứ ko sử dụng lại.
Cải thiện tốc load của UITableView.
Không nên sử dụng các hàm vẽ mà phải tính toán nhiều, đặc biệt là các hàm của QuartzCore framework, bởi vì các hàm này thường rất chậm, sẽ làm giảm tốc độ load của các cell.
Khi sử dụng TableView với các cell phức tạp, mà độ cao của cell phụ thuộc vào các content bên trong nó (VD như các news feeds của Facebook app), để cải thiện tốc độ load các cell này, hãy cùng học tập cách làm của Facebook: Trước hết, khi lấy được danh sách các feed, FB sẽ tính toán sẵn height cho từng cell một và lưu các giá trị này vào database (core data). Sau đó, khi load các cell, height của từng cell sẽ được lấy ra từ database. Điều này làm giảm hiện tượng thắt cổ chai khi mà nếu không tính toán height trước, table view sẽ vừa phải khởi tạo các component vừa phải tính toán chiều cao cho các cell. Đặc biệt là trong trường hợp danh sách các feed được lưu lại trên máy, và lần chạy app tiếp theo sẽ sử dụng lại các feed này => height cho các cell đã được tính toán từ trước.
Sử dụng multiple thread để giúp app chạy mượt mà hơn, tránh tình trạng bị treo. VD: main thread chỉ điều chỉnh UI và điều khiển các event tương tác với user. Các tác vụ tính toán nên để ở 1 thread khác, vd như các tác vụ network, JSON parsing, tạo và lưu database.
Năm nay năm âm là năm rắn, hồi tết mình ngồi rỗi không biết làm gì nên quyết định làm một game liên quan đến con rắn. Mà đã liên quan đến rắn thì chắc hẳn mọi người đều nhớ đến game cổ điển snake trên chiếc điện thoại nokia 1010. Để code xong cái đưa được cho bạn bè xem ngay, mình nghĩ làm trên javascript có lẽ là sự lựa chọn tốt nhất. Trong bài này mình sẽ giới thiệu về cách làm game snake trên javascript.
II. Thiết kế chương trình
Chỉ cần google với từ khóa “snake game trên javascript” cácbạn sẽ có khá nhiều kết quả với khác nhiều cách implement khác nhau cho đò họa. Có cách sử dụng canvas, có cách sử dụng đơn thuần css bình thường. Để làm cho nhanh thì mình sẽ sử dụng css.
Idea của game:
Game snake có dạng như sau:
Do đó chúng ta sẽ cần một bảng dạng “grid” để con rắn của chúng ta chạy. Bảng này có thể được implement một cách dễ dàng bằng table của html. Chúng ta sẽ tạo một table dynamically bằng code như dưới đây:
Như vậy chúng ta sẽ có cái grid view để con rắn của chúng ta chạy vòng quanh. Tiếp theo chúng ta sẽ design logic cho game. Về mặt idea, do chúng ta dùng css cho GUI, nên body con rắn của chúng ta sẽ được quản lý dưới dạng một array, mà mỗi element của array đó sẽ chứa 2 phần tử là row và col chính là vị trí của mỗi một khúc của thân con rắn. Với mỗi một step của Game loop, chúng ta sẽ vẽ những điểm có tọa độ nằm trong body con rắn với một màu nhất định.
Coding:
Để implement idea đó, chúng ta cần có một object Game. Trong object đó sẽ có các properties: snake_head (đầu con rắn), snake_body(array thân con rắn), snake_direction (hướng đi hiện tại, gồm có 4 hướng là left, right, up, down), fps (tốc độ di chuyển con rắn), và food (vị trí của thức ăn)
Ok như vậy là đã xong phần khung. Giờ đến đoạn di chuyển và ăn thức ăn của con rắn. Đầu tiên là về mặt di chuyển. Để di chuyển con rắn thì đầu tiên chúng ta phải catch event key và set direction cho nó. Việc này được thực hiện thông qua đoạn code dưới đây:
snake.js
123456789101112131415161718
Game.prototype.key_handler=function(evt){varself=this;vardiff=self.snake_direction-evt.keyCode;if(self.key_list.contains(evt.keyCode)){if(Math.abs(diff)!=2){/*logic này dùng để check việc khi snake đang di chuyển left thì người dùng bấm right (hoặc tương tự với đang di chuyển up bấm down...), khi đó thì con rắn của chúng ta sẽ không chuyển hướng*/self.snake_direction=evt.keyCode;}}}//binding key$('body').keydown(function(evt){snakeGame.key_handler(evt);})
Như vậy chúng ta đã có logic để khi người dùng bấm phím di chuyển con rắn chúng ta sẽ có direction thích hợp. Vấn đề là với direction đó con rắn của chúng ta sẽ di chuyển thế nào. Vấn đề đó được implement ở đoạn code dưới đây:
Game.prototype.set_body=function(){varself=this;vardirection=self.snake_direction;//set snake bodylen=this.snake_body.length;varhead_row=self.snake_body[len-1].row,head_col=self.snake_body[len-1].col;switch(direction){//set head pos with directioncaseself.keys.LEFT:head_col=head_col-1;break;caseself.keys.RIGHT:head_col=head_col+1;break;caseself.keys.UP:head_row=head_row-1;break;caseself.keys.DOWN:head_row=head_row+1;break;default:return;}varhead_pos=getat(head_row,head_col);//check game overif(head_pos.attr("type")==="snake"||head_row<1||head_col<1||head_row>boardsize||head_col>boardsize){self.end_game();return;}self.snake_body.push({row:head_row,col:head_col});//push headlen=self.snake_body.length;//if not get foodif(head_pos.attr("type")!=="food")self.snake_body=self.snake_body.slice(1,len);//cut tailelse{$("#score").html(parseInt($("#score").html())+1);self.set_food();}returntrue;}
Chúng ta có thể thấy gì từ đoạn code trên. Đầu tiên các bạn sẽ thấy chúng ta di chuyển con rắn bằng cách nào. Việc di chuyển con rắn được thưc hiện rất đơn giản. Với mỗi step di chuyển, chúng ta set vị trí mới cho đầu con rắn dựa vào direction tính được ở trên, và cắt cái đuôi của cái array đi. Rất đơn giản phải không :D. Ngoài ra ở đoạn code trên chúng ta cũng thấy, khi vị trí mới của đầu con rắn trùng với vị trí của thức ăn, thì chúng ta sẽ không cắt đuôi của array đi, và việc này đồng nghĩa với việc con rắn dài ra.
Đoạn code trên đồng thời cũng implement hệ thống tính điểm (mỗi lần ăn thức ăn là score increment thêm 1), và logic về khi con rắn đâm vào tường hoặc là đâm vào chính nó thì sẽ chết (ở đoạn //check game over)
Thêm thắt một chút css, chúng ta đã có một game con rắn hoàn chỉnh
Trước khi tìm hiểu về Avro, chúng ta cần nắm được serialization là gì. Theo wiki, Serialization là quá trình chuyển các cấu trúc dữ liệu và các đối tượng thành một định dạng có thể lưu trữ được (vào file, in-memory buffer, hoặc truyền qua network), sau đó có thể phục hồi lại các cấu trúc dữ liệu và đối tượng như ban đầu, trên cùng hoặc khác môi trường.
Tác dụng của Serialization gồm có: - đồng nhất hóa các đối tượng, để có thể lưu các thuộc tính của nó vào ổ cứng, hoặc cơ sở dữ liệu - dùng cho Remote procedure call (RPC)
Trong một số ngôn ngữ lập trình như Java, Ruby, Python, PHP, các ngôn ngữ .NET,…, Serialization được hỗ trợ trực tiếp. Bên cạnh đó, còn có những framework riêng cho Serialization, có thể kể đến: Google’s Protocol Buffers, Apache Thrift, và Apache Avro.
2. Tại sao dùng Apache Avro?
Nếu sử dụng các phương pháp serialization của từng ngôn ngữ (ví dụ như với Java, ta cần định nghĩa một class implement Serializable class), ta gặp phải vấn đề mất language portability: dữ liệu được serialize ra sẽ chỉ đọc được bởi ngôn ngữ tạo ra nó mà thôi! Apache Avro đã khắc phục nhược điểm này, vì đây là một hệ thống data serialization không phụ thuộc ngôn ngữ (language-neutral). Bằng cách xây dựng một định dạng dữ liệu có thể được nhiều ngôn ngữ xử lý, Avro đã giúp chia sẻ dataset với nhiều đối tượng sử dụng ngôn ngữ khác nhau hơn.
Nếu nói về language-neutral, thì Google’s Protocol Buffers và Apache Thrift cũng làm được như vậy. Vậy tại sao lại có thêm Apache Avro?
Những hệ thống này có đặc điểm chung là data được mô tả bằng schema, không phụ thuộc ngôn ngữ lập trình. Tuy nhiên, Protocol Buffers và Thrift cần phải có compiler riêng biệt để tạo ra các implementation tương ứng với từng ngôn ngữ lập trình. Quá trình này gọi là code generation. Còn đối với Avro, quá trình code generation chỉ là option, nghĩa là ta có thể đọc và ghi dữ liệu luôn theo một schema cho trước, kể cả code của ta chưa từng thấy schema đó bao giờ. Để làm được điều này, schema luôn xuất hiện kèm với data đã được serialized, ở cả lúc đọc và ghi. Cách mã hóa này rất gọn nhẹ, vì giá trị đã encode không cần phải tag cùng với các field identifier như Protocol Buffer.
3. Avro Data Types và Schemas
Lý thuyết tổng quan về Avro là như vậy, giờ ta hãy chuyển sang thực hành cho dễ hiểu. Chúng ta cùng bắt đầu bằng một ví dụ đơn giản. Định nghĩa một schema trong file Person.avsc như sau:
namespace, cùng với thuộc tính name, tạo ra full name của schema này. - type: ở đây là thuộc loại record.
name: tên của schema này.
fields: chỉ ra các trường trong record này (gồm có 3 trường name, age, address).
Avro cung cấp một số primitive types như sau: null, boolean, int, long, float, double, byte, và string. Ngoài ra còn có các complex types: record, enum, array, map, union, fixed.
Ở ví dụ này, để đơn giản, ta chỉ sử dụng 2 type là string và int.
Có file định nghĩa schema rồi, trong Java, chuyển thành đối tượng Schema như sau:
Name: Alex. Age: 24. Address: MI
Name: Betty. Age: 25. Address: NJ
Name: Carol. Age: 26. Address: WA
Có vài lưu ý trong đoạn code trên:
Ghi dữ liệu: DatumWriter dùng để chuyển đối tượng Java thành định dạng in-memory serialized. Ta cần có schema truyền vào đối tượng GenericDatumWriter, để biết ghi dữ liệu theo schema nào. Schema này ta có thể đọc ra từ file avsc, như trên đã trình bày. Sau đó, ghi đối tượng đã serialized cùng với schema vào datafile bằng cách sử dụng DatumFileWriter.
Đọc dữ liệu: vì đặc điểm của Avro Datafile là nó chứa luôn schema trong metadata của nó, do vậy khi đọc file, không cần chỉ ra schema mà lấy trực tiếp từ file cần đọc: reader.getSchema()
Định dạng của Avro Datafile: gồm phần header chứa metada, bao gồm Avro schema và sync marker, tiếp theo là một dãy block chứa các Avro object đã serialize. Các block này được ngăn cách bởi sync marker.
5. Đa ngôn ngữ
Như trên đã trình bày, Avro datafile là language-neutral, nghĩa là có thể chia sẻ giữa nhiều ngôn ngữ lập trình khác nhau. Ở đây, xin trình bày ví dụ đọc file test-person.avsc ở trên bằng Python:
Tương tự, đối với các ngôn ngữ khác (Ruby, PHP, các ngôn ngữ .NET…) , bằng cách sử dụng các Avro implementation tương ứng, việc đọc/ghi Avro datafile cũng dễ dàng tương tự như vậy.
6. Tóm tắt
Bài viết đã trình bày những bước căn bản để làm quen với Apache Avro. Trong bài viết tiếp theo, tôi sẽ trình bày cách sử dụng Avro trong hệ thống RPC (Remote Procedure Call) như thế nào.